3. Chapitre 1 — Axe technologique
Question 1 : comment des choix d’entraînement et de conception modifient-ils le comportement et la qualité des réponses d’une IA ?
3.1 Un peu d’histoire
Quand on parle d’intelligence artificielle aujourd’hui, on pense souvent à des outils comme ChatGPT ou des générateurs d’images. Mais l’idée de « machine intelligente » est beaucoup plus ancienne : dès les années 1950, des chercheurs se posent déjà la question « une machine peut-elle penser ? ». 1
Au début, l’IA est surtout symbolique : des règles écrites à la main (« si telle condition est vraie, alors fais ça »). Ça fonctionne pour des problèmes bien cadrés, mais on est très loin d’un chat qui répond à tout comme aujourd’hui.
Le gros changement arrive quand on passe à l’apprentissage automatique. Au lieu de tout programmer à la main, on donne au modèle énormément d’exemples (textes, images, etc.) et il apprend à repérer des motifs tout seul. Ensuite viennent le deep learning (méthode d’apprentissage automatique avancée, basée sur des réseaux de neurones, c’est-à-dire des systèmes inspirés du fonctionnement du cerveau) et, en 2017, les transformers (type de modèle d’IA pour traiter le texte), qui sont la base des modèles de langage modernes.2 Pour illustrer mes propos, voici une frise chronologique qui montre les grandes étapes de l’IA.
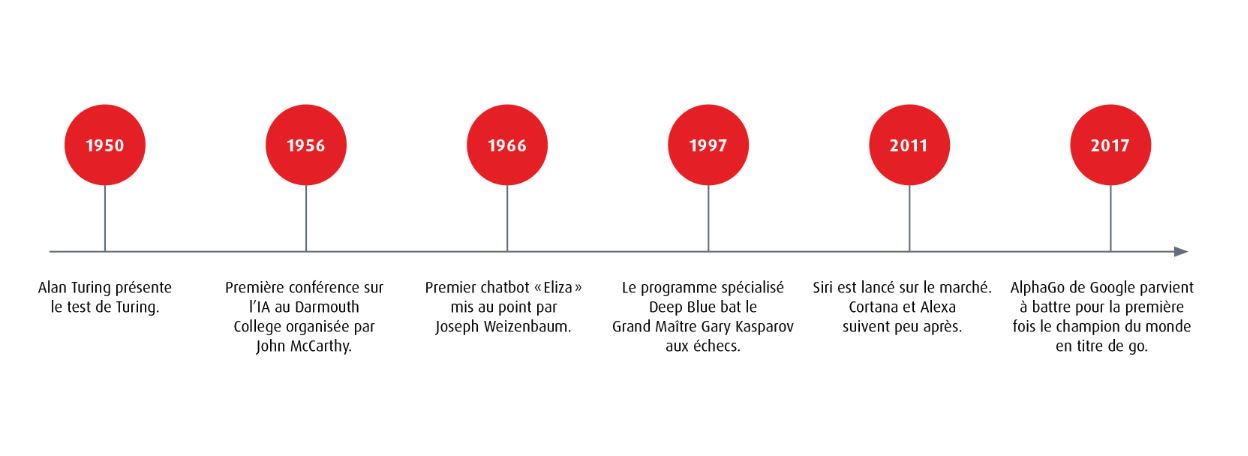
Dans mon TPA, quand je parle d’IA, je parle surtout de ces modèles de langage. Pour faire simple, ils prédisent mot par mot (ou morceau de mot par morceau de mot) la suite la plus probable d’un texte, en fonction de ce qu’on leur a donné comme consigne. Derrière cette idée assez simple, il y a une grosse machine technique qu’on va voir dans la partie suivante.
3.2 Comment on entraîne une IA (version simplifiée)
Pour qu’une IA comme ChatGPT fonctionne, il ne suffit pas d’appuyer sur un bouton magique. Il y a une vraie « recette » technique derrière. Je résume ici les grandes étapes, sans rentrer dans les maths.
1) Récupérer des données
D’abord, il faut beaucoup de données. Pour un modèle de langage, ce sont surtout des textes : pages web, livres, documentations, forums, etc. On nettoie ces données (enlever les doublons, le spam, certains contenus) pour obtenir un gros corpus (grand ensemble de textes ou de données) utilisable.
2) Transformer les mots en nombres
L’ordinateur ne comprend pas directement les mots. On transforme donc le texte en une suite de nombres. On découpe le texte en petits morceaux (appelés « tokens », c’est-à-dire de petits morceaux de texte traités par l’IA) et chaque token est représenté par un numéro. Tout l’entraînement se fait ensuite sur ces nombres.
3) Entraîner le modèle
Là, on arrive au cœur du processus. L’idée est la suivante : on montre au modèle un bout de phrase, il essaie de deviner la suite, et on lui dit à quel point il s’est trompé. En fonction de ça, il ajuste ses paramètres (ce sont des nombres internes, autrement dit les réglages internes du modèle, qui déterminent la façon dont il transforme l’entrée en sortie).
On répète cette boucle des millions de fois sur des tonnes de textes. Petit à petit, le modèle s’améliore et devient capable de produire des réponses cohérentes. Tout ça demande énormément de calculs et donc beaucoup d’électricité.3
4) Pourquoi on parle tout le temps de GPU ?
Pour faire tourner ce type de modèle, on utilise surtout des GPU. À la base, ce sont des cartes graphiques pour les jeux vidéo, mais elles sont très bonnes pour faire plein de petits calculs en parallèle. C’est exactement ce qu’il faut pour l’entraînement de grands modèles d’IA.
Dans un data center, il peut y avoir des rangées entières de serveurs remplis de GPU qui calculent jour et nuit. La demande est tellement forte que certains fabricants donnent la priorité aux gros clients (centres de données, grandes entreprises) et beaucoup moins au grand public, ce qui crée des tensions sur le marché du matériel.4
5) Entraînement vs utilisation au quotidien
On peut distinguer deux phases :
- l’entraînement : très coûteux en temps, en électricité et en matériel ; c’est là qu’on ajuste tous les paramètres du modèle ;
- l’utilisation (quand je pose une question dans un chat) : beaucoup moins chère qu’un entraînement complet, mais répétée des milliards de fois par jour, donc l’impact global reste important.
Atelier guidé : « Construis ton IA pas à pas »
Réponds aux questions dans l’ordre. À chaque étape, une réponse pré-écrite explique ce que tes choix changent.
Chargement de l’atelier…
3.3 Aujourd’hui en 2025 — les outils qu’on utilise
En 2025, l’IA n’est plus juste un sujet de labo. On la retrouve un peu partout : assistants de texte comme ChatGPT, générateurs d’images, systèmes de recommandation de vidéos, correcteurs orthographiques améliorés, outils de résumé, etc. Une étude sur les usages réels montre que beaucoup de gens s’en servent surtout pour rédiger, résumer, brainstormer et gagner du temps dans leur travail.5
Comme élève en informatique, je le vois très concrètement avec des outils comme GitHub Copilot. Il s’intègre dans l’éditeur de code et propose des complétions ou des fonctions entières à partir de quelques lignes ou d’un commentaire. Je tape moins de code « à la main », mais je dois lire, comprendre et vérifier ce que l’IA me propose. La manière de coder change complètement.
L’IA débarque aussi dans des domaines plus « classiques ». Par exemple, dans le secteur de la construction, on commence à l’utiliser pour optimiser des plans, surveiller des chantiers ou détecter des problèmes potentiels plus tôt, ce qui change peu à peu la manière de travailler sur le terrain.6
Pour ce TPA, j’utilise moi-même l’IA comme outil de travail. Par exemple pour m’aider à reformuler certains passages, à structurer mes idées ou à vérifier des explications techniques. Mais au final, je dois toujours relire, corriger, et adapter pour que le texte me ressemble et reste compréhensible pour quelqu’un qui n’est pas forcément du milieu de l'informatique.
3.4 Limites et risques techniques
Même si les résultats sont parfois impressionnants, les IA ont des limites techniques importantes. Ce ne sont pas des humains dans une boîte, mais des modèles qui complètent du texte en fonction de ce qu’ils ont vu pendant l’entraînement.
- Erreurs et hallucinations (réponses inventées mais plausibles) : le modèle peut inventer des faits ou donner des réponses fausses avec beaucoup de confiance. Dans certains domaines sensibles (comme la santé mentale), on a déjà vu des exemples où des jeunes suivent des conseils d’IA de manière très sérieuse, ce qui peut être dangereux voire dramatique.7
- Bugs et usages illégaux : du code généré automatiquement peut contenir des failles de sécurité, des erreurs logiques ou réutiliser du code protégé. Si on ne relit pas, on peut se retrouver avec des applications instables ou qui posent des problèmes juridiques.
- Consommation d’électricité : l’infrastructure nécessaire (entraînement + usage au quotidien) consomme beaucoup d’énergie et a un impact réel sur le climat, même si on ne le voit pas quand on tape une simple question dans un chat.3
- Biais (tendances à produire des réponses orientées ou injustes) et influence de la culture : si les données d’entraînement sont biaisées, les réponses le seront aussi. Des autorités comme la CNIL rappellent que certains algorithmes peuvent discriminer sans que ce soit volontaire, juste à cause des données ou du design du système.8
Au final, les choix techniques ne sont jamais neutres : ils dépendent de priorités (performance, coût, sécurité, image de marque, etc.). Comme l’IA est utilisée par des millions de personnes, ces choix ont des effets très concrets sur ce que le modèle accepte ou refuse de dire.
C’est ce qui mène directement au chapitre suivant : qui décide de ce qui est autorisé ou interdit ? Comment se construisent les règles de modération, et qu’est-ce que ça change dans les réponses qu’on reçoit ? C’est le cœur de l’axe politique / légal.
3.5 Notes de bas de page et sources du chapitre 1
- THAT’S AI, « L’histoire de l’IA », That’s AI, s.d., https://www.thats-ai.org/fr-CH/units/l-histoire-de-l-ia (consulté le 10.12.2025). ↑
- VASWANI, Ashish; SHAZEER, Noam; PARMAR, Niki; et al., « Attention Is All You Need », Advances in Neural Information Processing Systems, 30, 2017, https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (consulté le 10.12.2025). ↑
- ZEWE, Adam, « Explained: Generative AI’s environmental impact », MIT News, 17 janv. 2025, https://news.mit.edu/2025/explained-generative-ai-environmental-impact-0117 (consulté le 10.12.2025) ; STRUBELL, Emma; GANESH, Ananya; MCCALLUM, Andrew, « Energy and Policy Considerations for Deep Learning in NLP », Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, https://aclanthology.org/P19-1355/ (consulté le 10.12.2025). ↑1 ↑2
- DIGITEC, « Le boom de l’IA entraîne une pénurie de mémoire et une hausse des prix », Digitec, 17 nov. 2025, https://www.digitec.ch/fr/page/le-boom-de-lia-entraine-une-penurie-de-memoire-et-une-hausse-des-prix-40480 (consulté le 17.03.2026) ; REUTERS, « The AI frenzy is driving a memory chip supply crisis », Reuters, 2 déc. 2025, https://www.reuters.com/world/china/ai-frenzy-is-driving-new-global-supply-chain-crisis-2025-12-03/ (consulté le 17.03.2026). ↑
- ZAO-SANDERS, Marc, « How People Are Really Using Gen AI in 2025 », Harvard Business Review, avril 2025, https://hbr.org/2025/04/how-people-are-really-using-gen-ai-in-2025 (consulté le 10.12.2025). ↑
- BAUMEISTER, « L’intelligence artificielle dans la construction », Baumeister, s.d., https://baumeister.swiss/fr/lintelligence-artificielle-dans-la-construction/ (consulté le 10.12.2025). ↑
- MCBAIN, Ryan K.; BOZICK, Robert; DILIBERTI, Melissa; et al., « Use of Generative AI for Mental Health Advice Among US Adolescents and Young Adults », JAMA Network Open, 8(11), 2025, https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2841067 (consulté le 10.12.2025). ↑
- COMMISSION NATIONALE DE L’INFORMATIQUE ET DES LIBERTÉS ; DÉFENSEUR DES DROITS, « Algorithmes et discriminations : le Défenseur des droits et la CNIL appellent à une mobilisation », Site de la CNIL, 2020, https://www.cnil.fr/fr/algorithmes-et-discriminations-le-defenseur-des-droits-avec-la-cnil-appelle-une-mobilisation (consulté le 10.12.2025). ↑